Jenkins는 자동화된 빌드 → 테스트 → 배포를 수행하는 인기 있는 오픈소스 CI/CD 도구이다.
규모가 커지고 파이프라인이 복잡해질수록 Jenkins의 빌드 현황이나 성공률, 실패 건수, 대기 시간 같은 주요 지표를 실시간으로 모니터링하는 게 점점 더 중요해지고 있다.
Jenkins 상태 모니터링이 중요한 이유는?
- 장애 대응 시간 줄이기:
빌드가 실패하거나 대기 시간이 급격히 늘어나는 등 이상 징후를 바로 파악해 빠르게 문제에 대응할 수 있다. - 운영 효율성 향상:
자주 발생하는 에러나 병목 구간이 보이면, 파이프라인을 개선 방향을 쉽게 찾을 수 있다. - 투명한 커뮤니케이션 및 협업:
개발자뿐 아니라 QA, 인프라팀까지 누구나 현재 Jenkins에 무슨 일이 있는지 직관적으로 볼 수 있다. - 지속적인 개선:
빌드 성공률, 평균 빌드 시간, 실패 패턴 같은 데이터가 쌓이면, 지속적으로 프로세스나 인프라를 개선할 수 있다.
Jenkins 모니터링, 어떻게 구성할까?
1. Jenkins 플러그인 기반 대시보드
Build Monitor View, Test Results Analyzer, Blue Ocean 같은 Jenkins 플러그인을 설치하여 Jenkins 대시보드에서 시각화하는 방식이다.
- 장점 : Jenkins에서 바로 설치하고 구성할 수 있어 빠르고 간편하다.
- 단점 : 성공률이나 Job별 상세 통계, 커스텀 대시보드를 구성하기에는 한계가 있어, 대규모 환경이나 장기 추세분석으로 활용하기에는 부족하다.
2. 외부 모니터링 툴 연동 (Prometheus + Grafana 등)
Jenkins에서 메트릭을 Prometheus로 보내고, Grafana에서 시각화하는 방식이다.
- 장점 :
- 성공/실패율, 평균 빌드 시간, Job별 상세 통계 등 다양한 지표를 시각화하여 한눈에 볼 수 있다.
- 장기 추세, SLA 준수 현황 등 체크가 가능하여 엔터프라이즈 환경에서 사용할 수 있다.
- 단점 : 외부 툴에 대한 사용 방법을 알아야 하기 때문에 초기 환경 구성 및 연동이 다소 복잡할 수 있다.
쿠버네티스 환경에서 많이 쓰는 모니터링 도구로는 Prometheus + Grafana가 있다.
실습에서는 Jenkins, Prometheus, Grafana가 설치되어 있다는 전제하에 아래 그림과 같이 Jenkins의 빌드 상태를 대시보드로 시각화하는 과정을 다룰 예정이다.
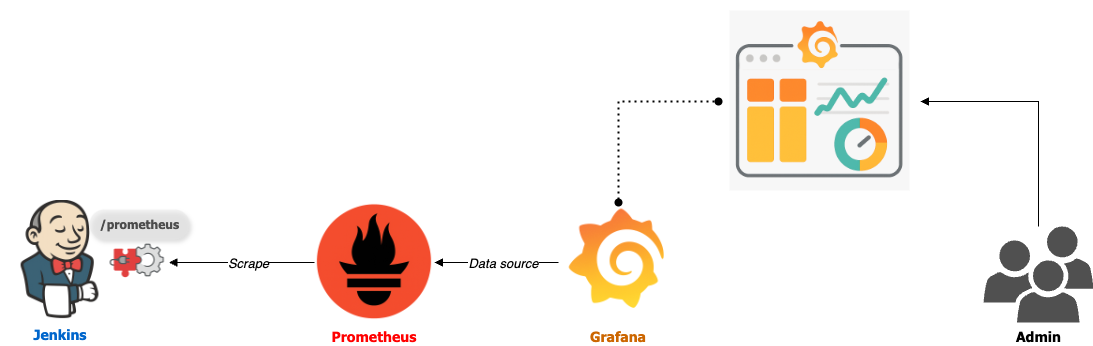
만약 Prometheus와 Grafana 설치부터 필요하다면, "Prometheus + Grafana 초간단 설치" 글을 참고하고,
Jenkins 설치부터 필요하다면, "Jenkins란? 개념부터 설치 실행까지 (쿠버네티스 환경)" 글을 참고하여 설치하면 실습 환경을 만들 수 있을 것이다.
구성 환경
- Amazon EKS: 1.31
- Jenkins: 4.11.1
- Prometheus metrics plugin: 819.v50953a_c560dd
- kube-prometheus-stack: v0.82.2
전제 조건
- Jenkins 구성
- Prometheus + Grafana 구성
- Kubernetes 클러스터
- Kubectl CLI
- Helm CLI
1. Prometheus metrics plugin 설치 & 구성
먼저 Jenkins 대시보드에서 Prometheus metrics plugin을 설치해야 한다.
- Dashboard → Jenkins 관리 → Plugins → Available plugins
- 검색창에 prometheus를 입력해서 Prometheus metrics plugin을 찾아 설치한다.

설치가 완료되면 Jenkins를 재시작한다.
재시작이 끝나면, 아래처럼 Prometheus 메트릭 관련 설정을 확인할 수 있다.
- Dashboard → Jenkins 관리 → System
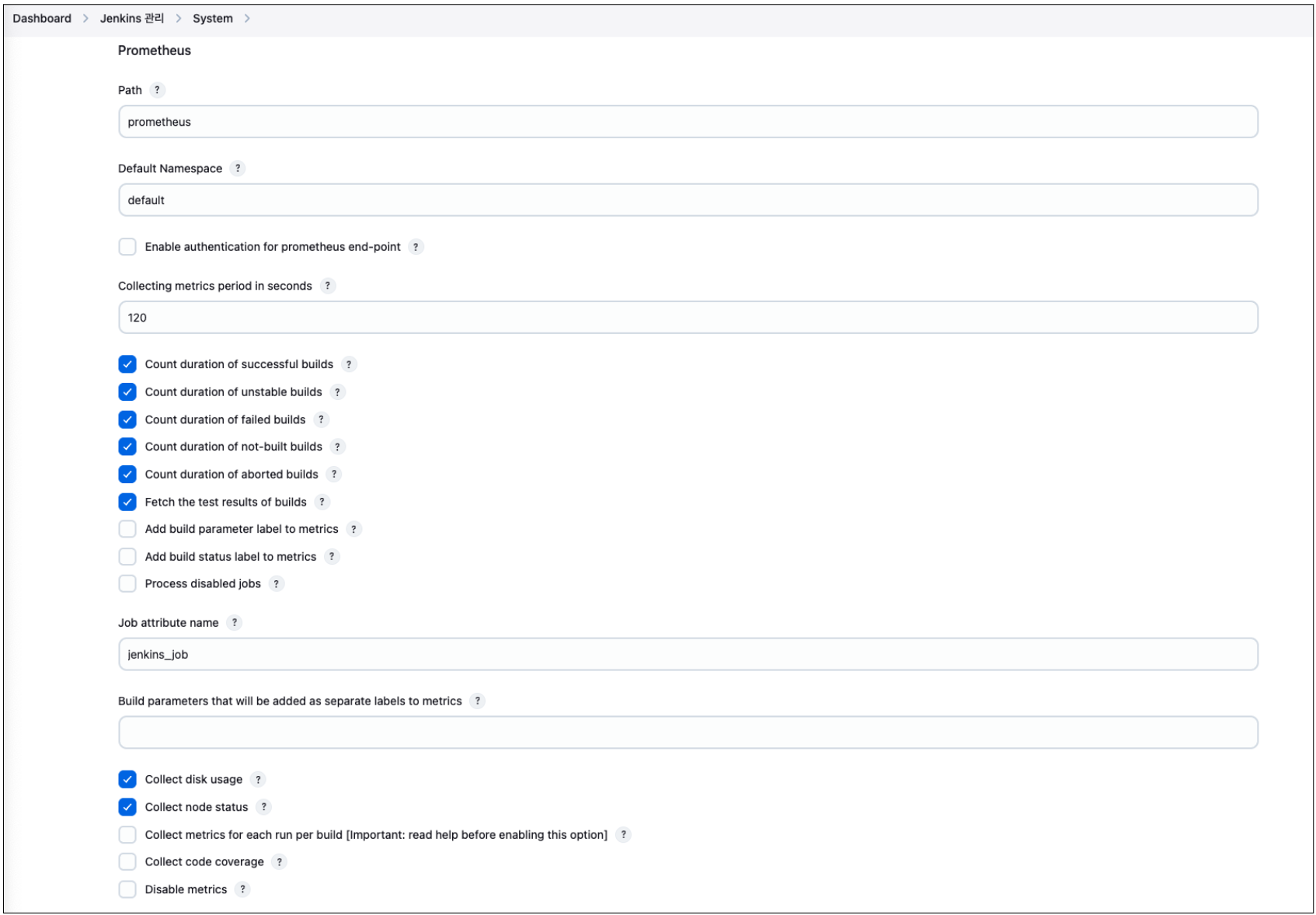
기본 체크 된 주요 옵션은 아래와 같다.
- Collecting metrics period in seconds
- Jenkins가 내부적으로 메트릭 데이터를 얼마나 자주 수집해서 /prometheus 엔드포인트로 노출할지 정하는 주기 설정이다. 실시간성이 중요하면 값을 더 짧게 설정한다.
- Count duration of [successful/failed/unstable/not-built/aborted] builds
- 각 빌드 상태별로 빌에 걸린 소요 시간을 집계해서 메트릭으로 보여줄지 여부.
- Fetch the test results of builds
- 빌드별 테스트 결과를 Prometheus로 넘길지 여부.
- Collect disk usage
- Jenkins 서버의 디스크 사용량을 메트릭으로 수집할지 여부.
- Collect node status
- Jenkins 에이전트(노드)들의 상태 정보를 메트릭으로 수집할지 여부.
2. Prometheus 메트릭 스크랩 설정
현재 배포되어 있는 Jenkins의 label을 확인한다.
이 label 정보는 뒤에서 작성할 Prometheus의 ServiceMonitor에서 사용할 예정이다.
$ kubectl get svc -n jenkins jenkins -o jsonpath="{.metadata.labels}"
{"app.kubernetes.io/component":"jenkins-controller","app.kubernetes.io/instance":"jenkins","app.kubernetes.io/managed-by":"Helm","app.kubernetes.io/name":"jenkins","helm.sh/chart":"jenkins-4.11.1"}
위에서 출력된 label 중 하나를 선택해서, 아래처럼 selector 부분에 입력하여 ServiceMonitor 리소스를 생성한다.
Jenkins에 Prometheus 플러그인을 설치하면 /prometheus 엔드포인트가 자동으로 노출되기 때문에, ServiceMonitor의 path도 이 엔드포인트로 입력한다.
$ cat <<EOF | kubectl apply -f -
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: jenkins-servicemonitor
namespace: jenkins
spec:
selector:
matchLabels:
app.kubernetes.io/component: jenkins-controller # Jenkins service label
endpoints:
- port: http
path: /prometheus # Jenkins의 Prometheus 엔드포인트
interval: 30s
EOF
ServiceMonitor가 정상적으로 동작하면, Prometheus가 Jenkins 메트릭을 제대로 수집하는지 아래 명령어로 로그를 확인할 수 있다.
$ kubectl logs -n monitoring sts/prometheus-prometheus-kube-prometheus-prometheus
# ... 생략 ...
level=INFO source=kubernetes.go:321 msg="Using pod service account via in-cluster config" component="discovery manager scrape" discovery=kubernetes config=serviceMonitor/jenkins/jenkins-servicemonitor/0
# ... 생략 ...
3. Jenkins 상태에 대한 Grafana 대시보드 구성
이제 Grafana에 접속해서, Prometheus에서 수집된 Jenkins 메트릭을 대시보드로 시각화해 보자.
- Grafana 접속 → HOME → Dashboards → New dashboard
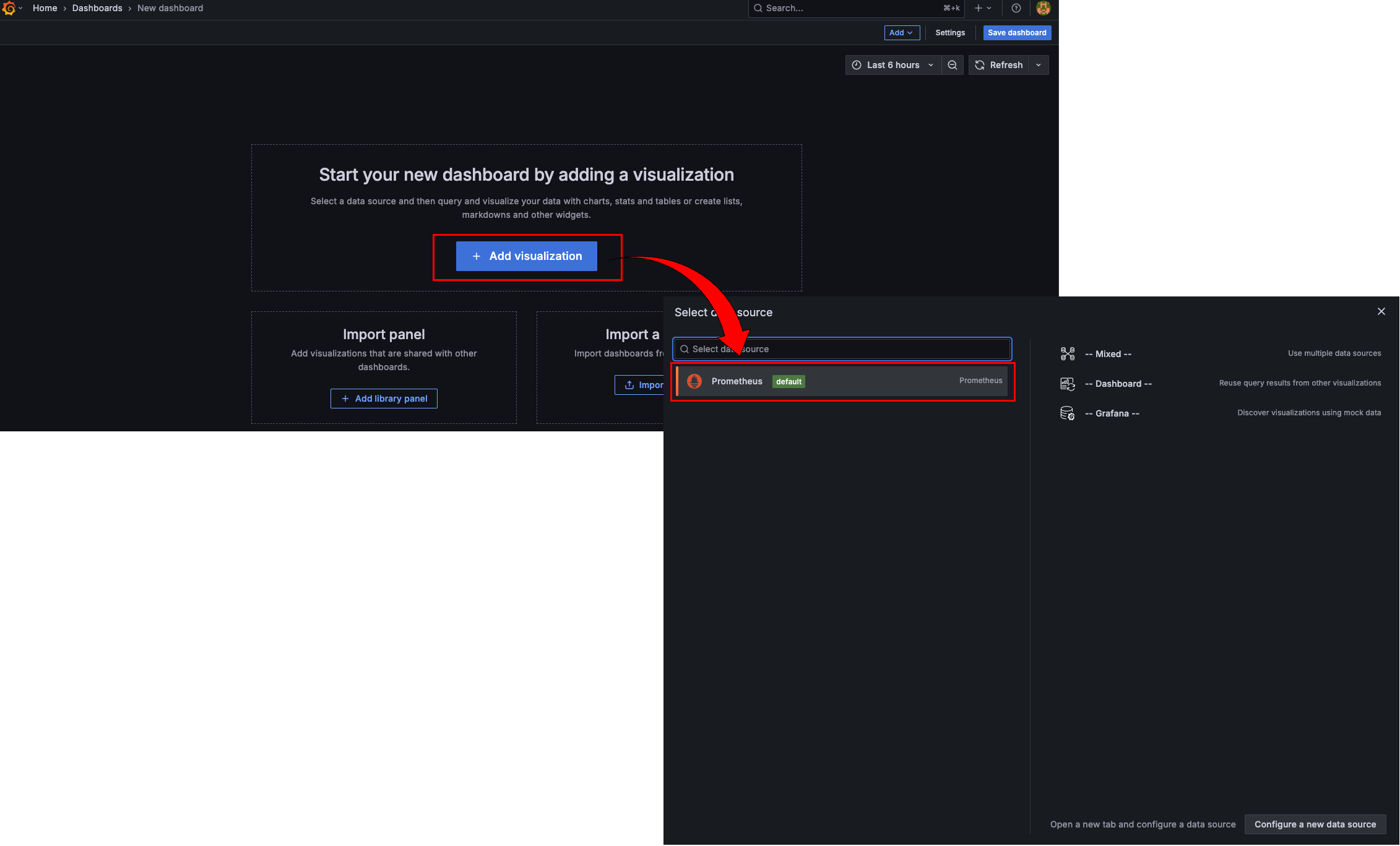
PromQL 입력창에 jenkins라고 입력하면 수집된 메트릭 리스트가 자동완성으로 나온다.
만약 아무것도 안 나온다면 수집 설정에 문제가 있을 수 있으니 앞서 한 설정을 다시 한 번 점검해야 한다.

전체 jenkins 파이프라인 Job 실행 횟수를 추가한다.
- Visualization: Stat
- Metrics browser: jenkins_runs_total_total
- Title: Total Jobs
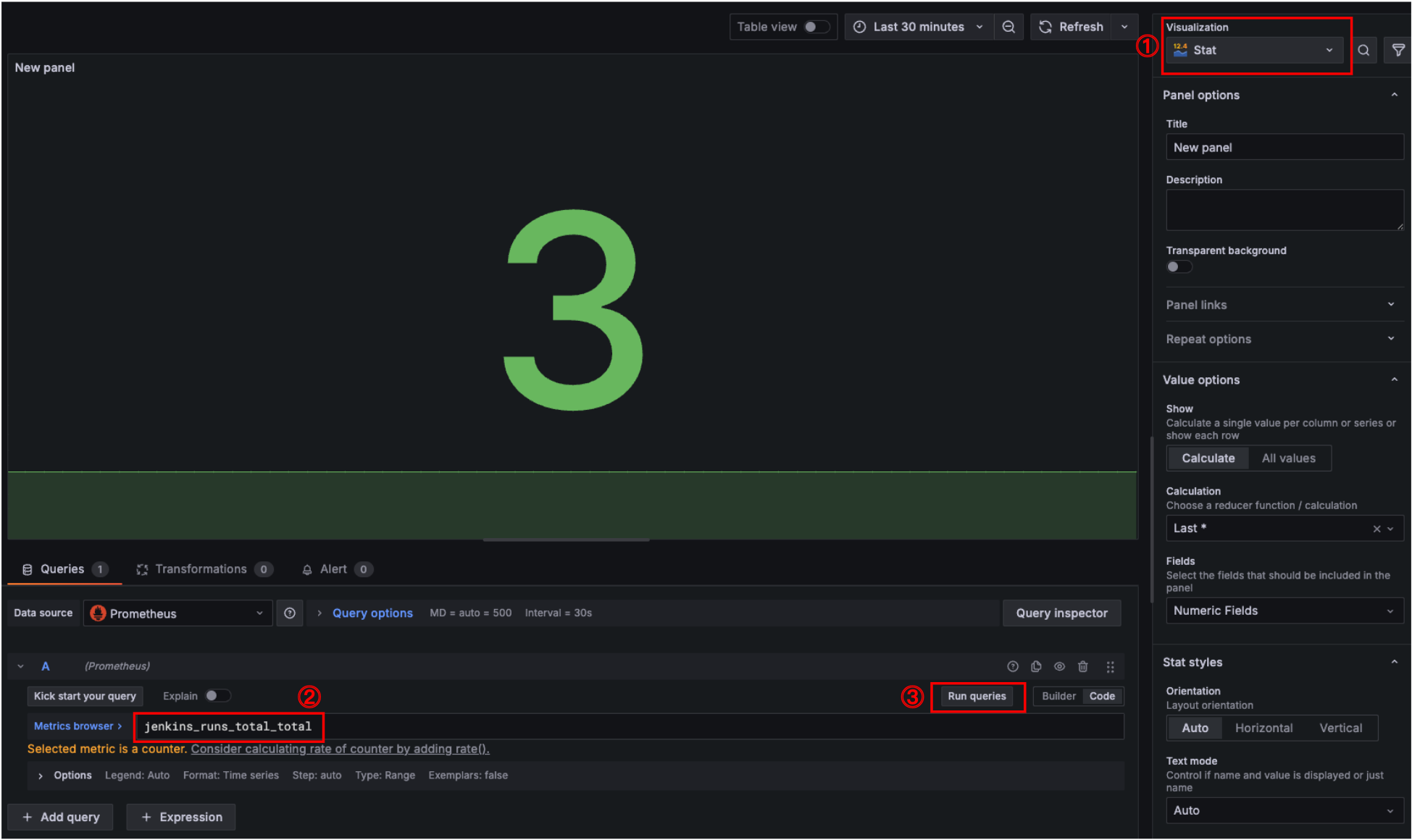
Back to dashboard를 눌러 대시보드로 돌아간 뒤, 새로운 패널을 생성한다.
- Add → Visualization
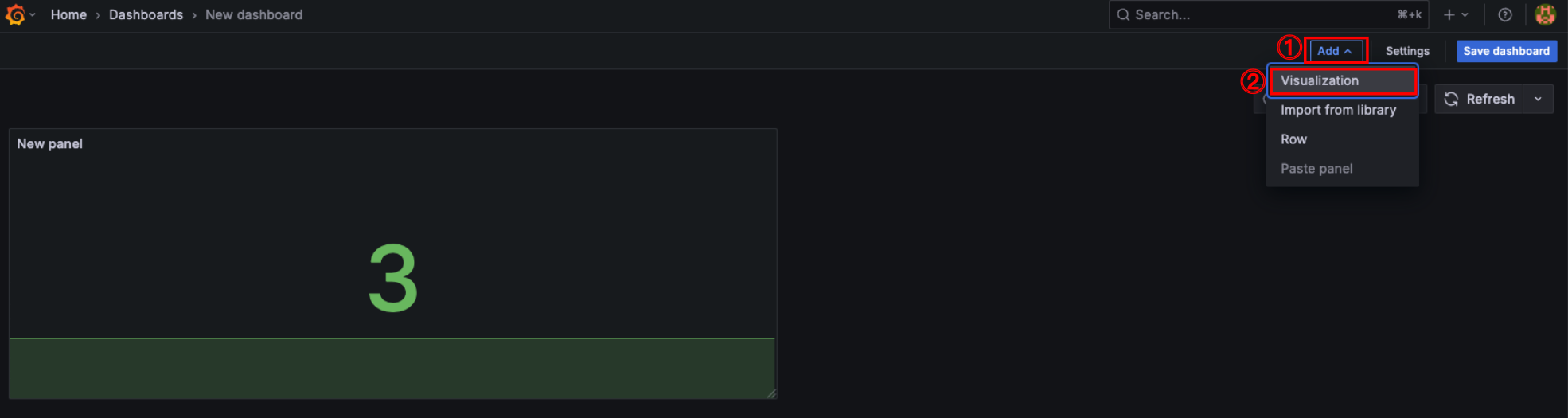
jenkins 파이프라인 Job에서 성공한 횟수를 추가한다.
- Visualization: Stat
- Metrics browser: jenkins_runs_success_total
- Title: Sucessful Jobs

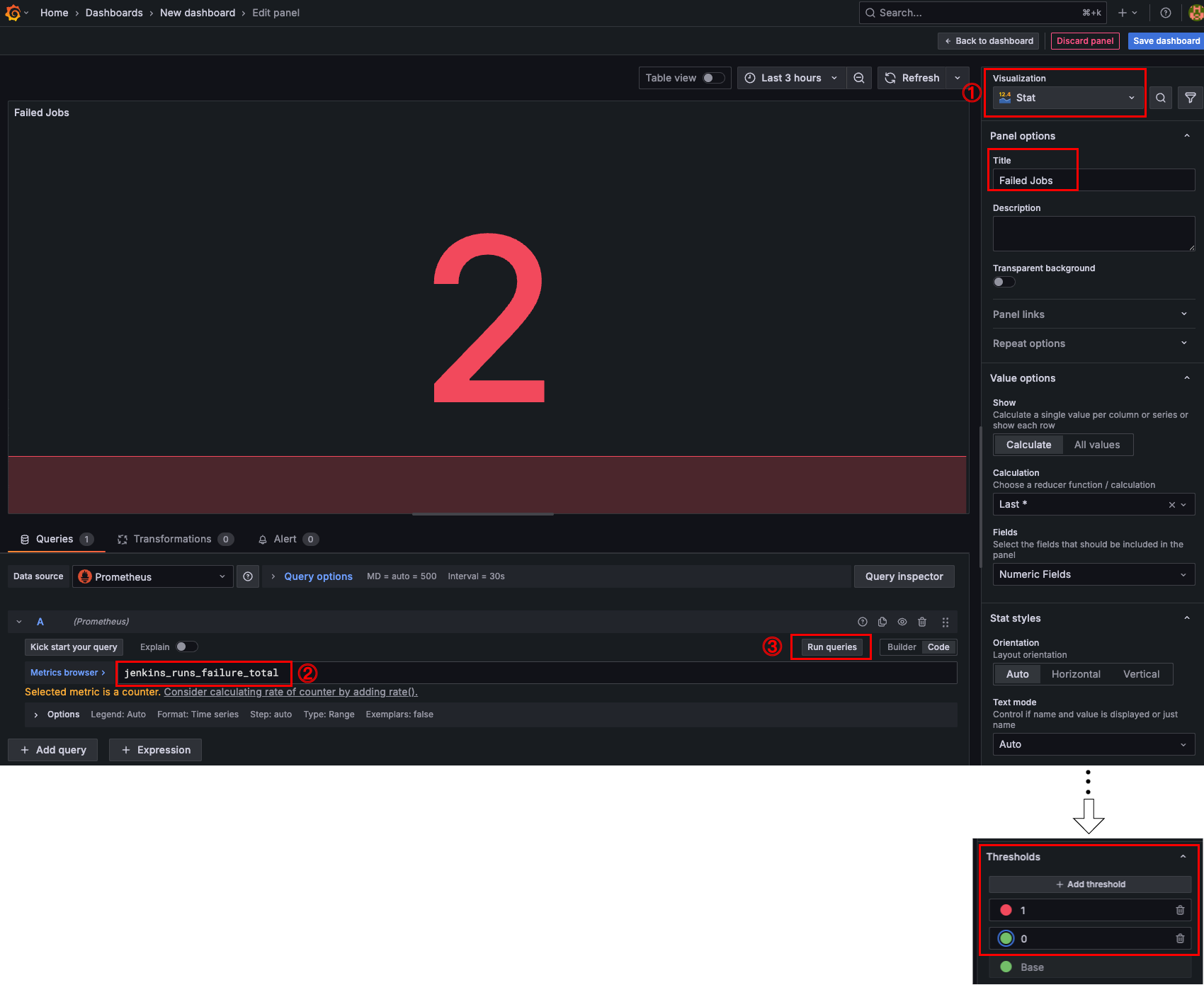
앞서 진행했던 것처럼 jenkins 파이프라인 Job에서 성공한 횟수 패널을 추가한다.
- Visualization: Stat
- Metrics browser: jenkins_runs_success_total
- Title: Failed Jobs
- Thresholds: Red 1 / Green 0 (실패가 1 이상이면 빨간색, 0이면 초록색)
Back to dashboard를 클릭하여 대시보드로 돌아가 지금까지 생성한 패널 정보를 저장한다.
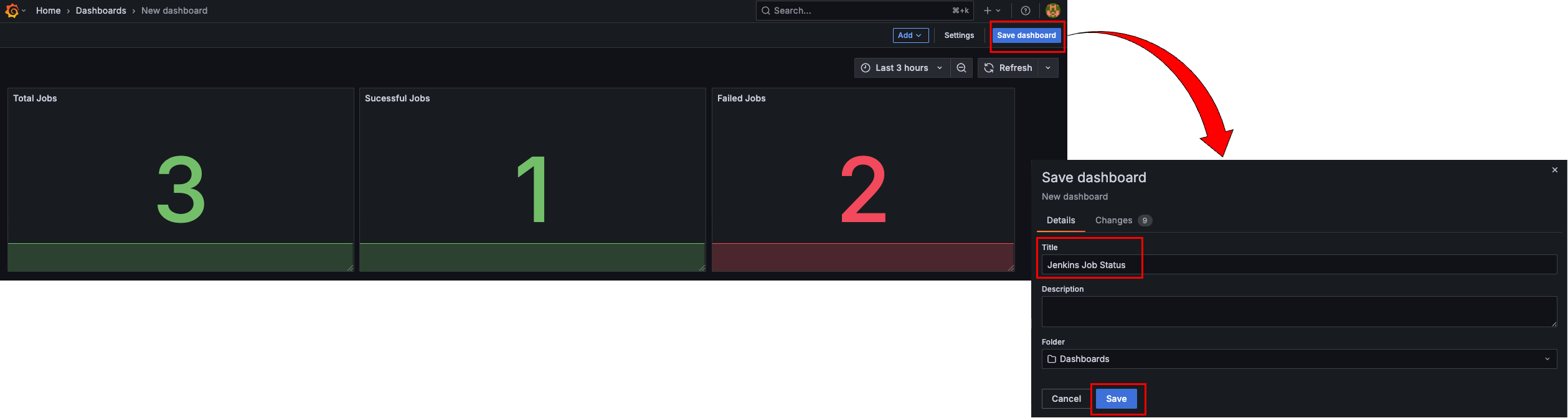
실제 Jenkins 파이프라인 job 결과와 대시보드 숫자가 일치하는지 비교해 보자.
전체 3, 성공 1, 실패 2 결과가 일치하다는 것을 확인할 수 있다.
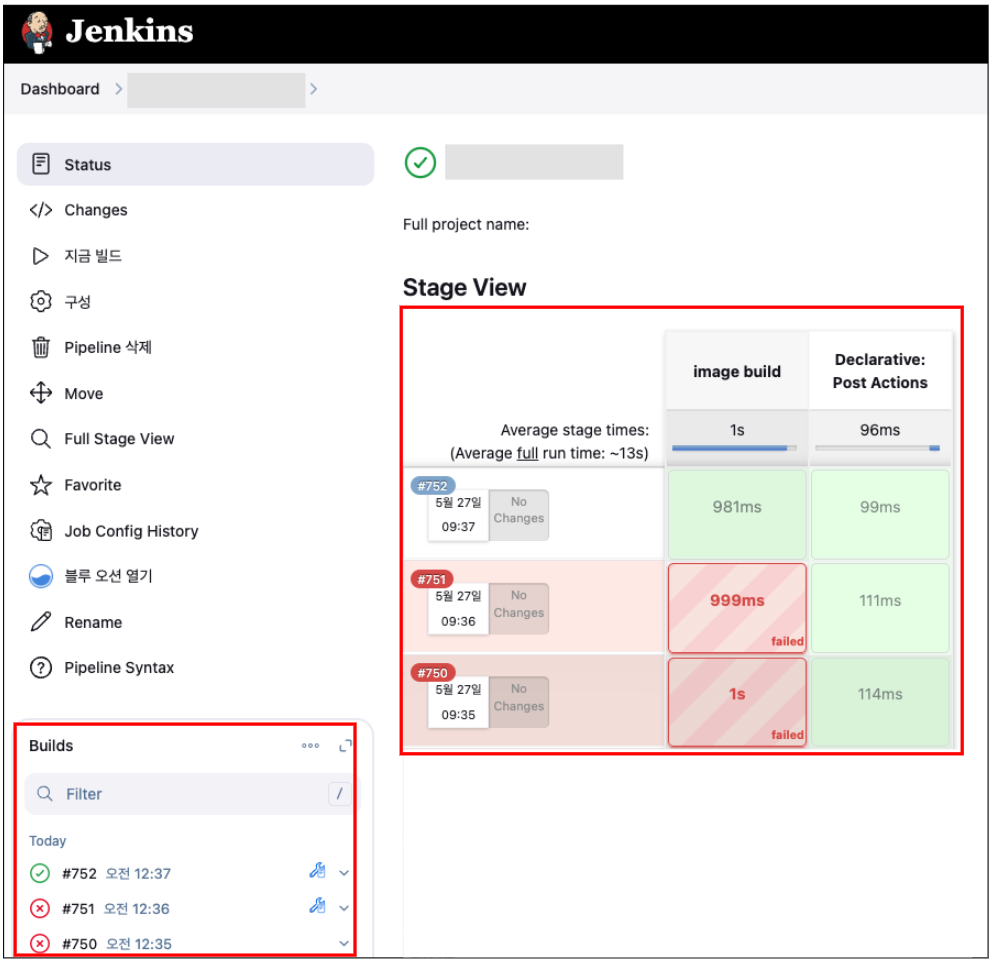
4. Jenkins 메트릭 값 검증하기
앞서 Grafana에 설정했던 메트릭 지표가 정확한지 Jenkins 파이프라인 job을 실행해 보면서 검증해 볼 것이다.
Jenkins 파이프라인 Job을 실행하면서 Grafana에 띄워둔 대시보드 메트릭 값이 제대로 반영되는지 확인해 보자.
아래는 Jenkins 빌드를 실행하여 job #753 이 성공한 그림이다.
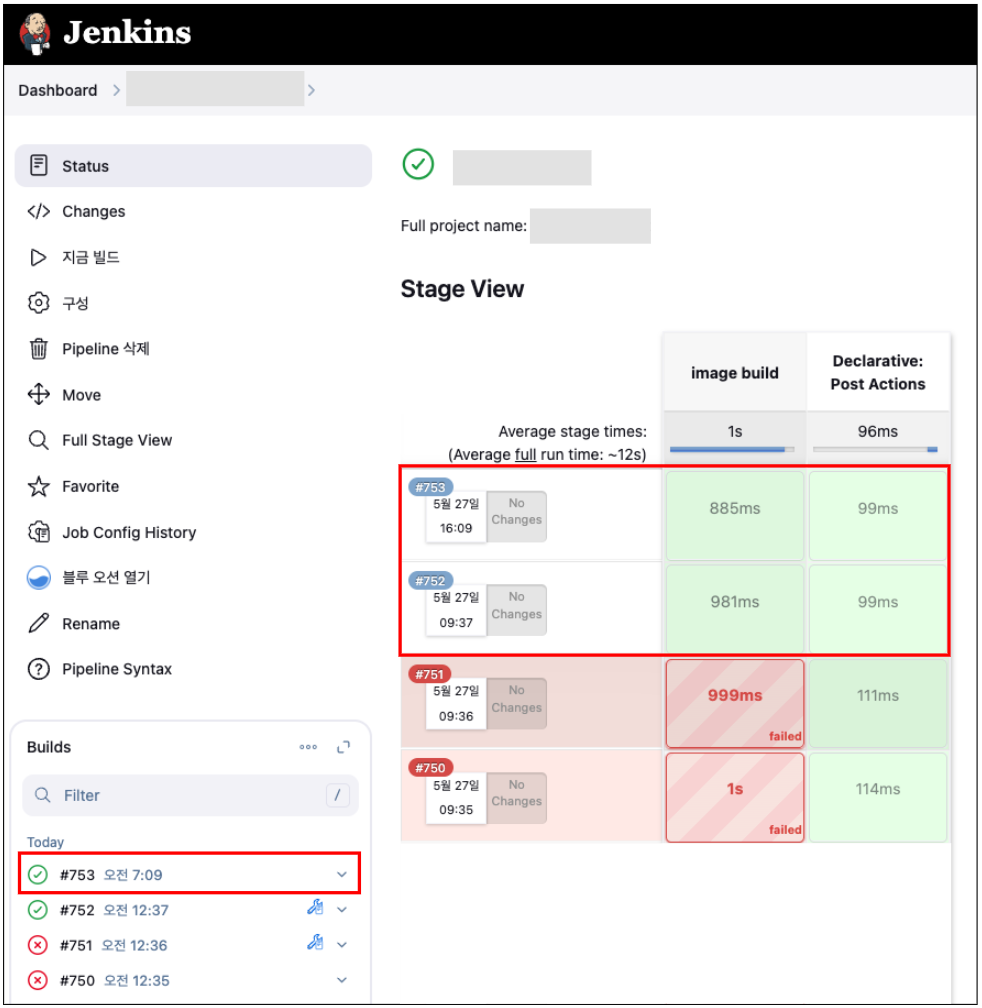
Grafana 대시보드에서 Total Jobs와 Successful Jobs(성공한 job) 값이 증가하는 걸 바로 확인할 수 있다.
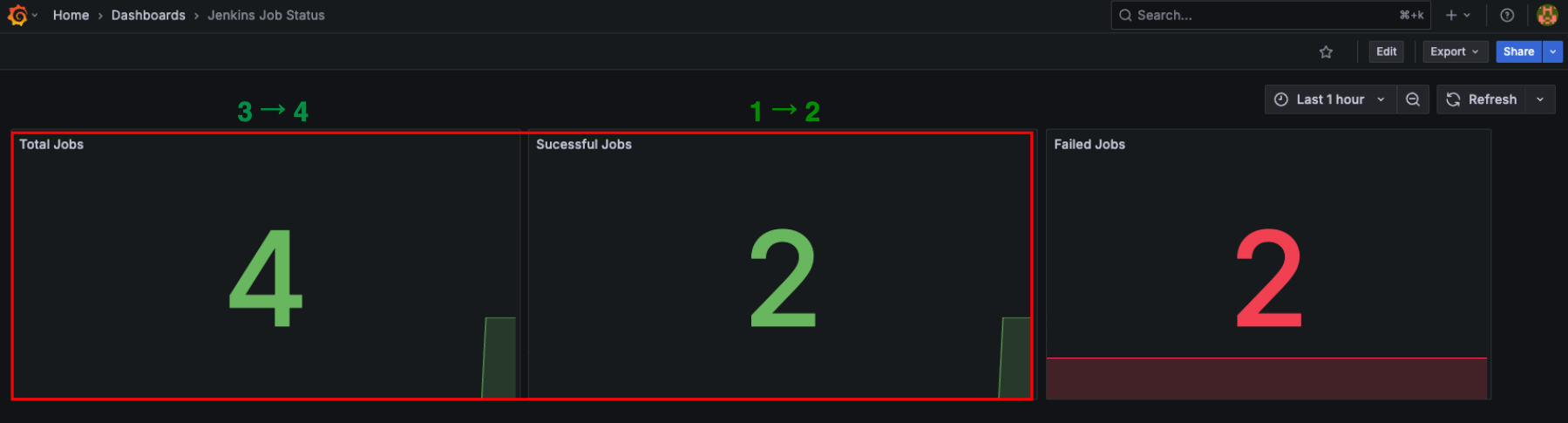
이번에는 Jenkins에서 빌드를 일부러 실패하도록 만든다.

Grafana 대시보드에서 Total Jobs, Failed Jobs 값이 증가한 것도 확인할 수 있다.

5. Jenkins 메트릭 대시보드 추가 구성
5-1. Unstable 상태와 Aborted 상태 지표
Jenkins 빌드의 Unstable 상태와 Aborted 상태에 대한 지표를 대시보드에 추가해 보자.
- Aborted: 파이프라인 빌드가 실행 중일 때 사용자가 "중단(Stop)" 버튼을 누르거나, Timeout, abort 명령 등 외부에서 강제 종료될 때 발생한다.
- Unstable: 빌드 자체는 실패하지 않았지만, 테스트 일부가 실패하는 등 완전 성공은 아닌 상태로, 테스트 일부가 실패했을 때 발생한다.
이 두 가지 상태를 강제로 만들어보고, 대시보드에 값이 반영되는지 확인해 보자.
- unstable 생성
파이프라인 코드에서 아래와 같이 currentBuild.result = 'UNSTABLE'를 명시적으로 추가한다.
script {
currentBuild.result = 'UNSTABLE'
}
- arbort 생성
파이프라인 코드에서 아래와 같이 currentBuild.result = 'ABORTED'를 명시적으로 추가한다.
script {
currentBuild.result = 'ABORTED'
}
post 블록에 아래와 같이 각 상태에 대한 내용을 추가한다.
# ... 생략 ...
post {
success {
echo 'Pipeline completed successfully!'
}
unstable {
echo 'Pipeline completed with some test failures.'
}
failure {
echo 'Pipeline failed.'
}
aborted {
echo 'Pipeline was aborted.'
}
}
# ... 생략 ...
위 설정을 한 후 각각 Unstable 상태와 Aborted 상태 job을 강제로 발생시켜 보자.

Grafana 대시보드에서 확인해 보면 다음과 같이 Unstable, Aborted 횟수가 증가한 것을 확인할 수 있다.
Metrics borwser:
- Unstable: jenkins_runs_unstable_total
- Aborted: jenkins_runs_aborted_total

5-2. Jenkins job 마지막 빌드 실행 소요시간 지표
Jenkins job별 마지막 빌드가 얼마나 걸렸는지 실행 소요시간을 대시보드에 추가해 보자.
- Visualization: Table
- Metrics borwser: default_jenkins_builds_last_build_duration_milliseconds
- Transformations: Organize fields by name
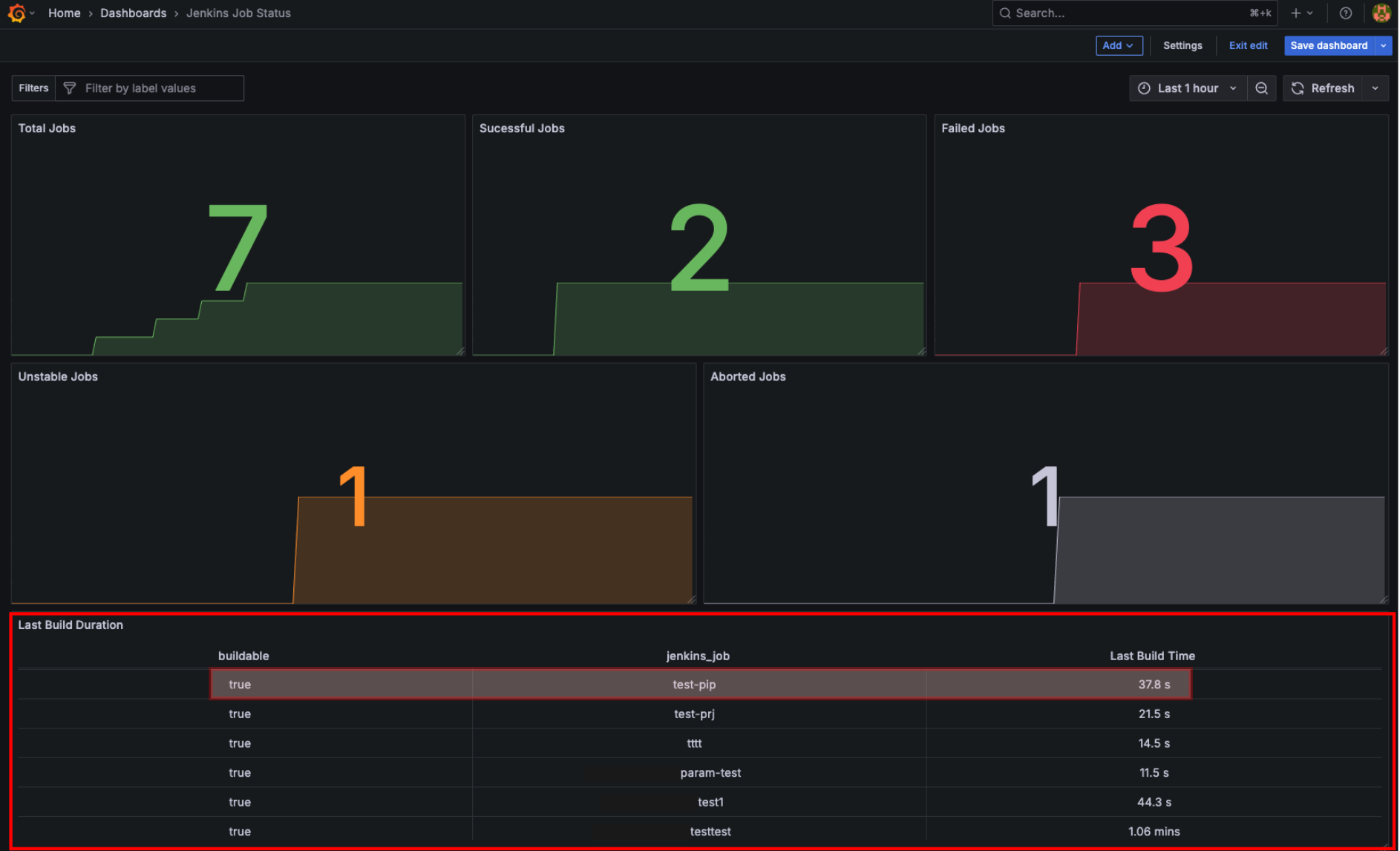
실제로 Jenkins job을 실행해 보고, 마지막 실행 소요시간을 확인해 보면, 값이 동일하다는 것을 확인할 수 있다.

5-3. Jenkins 마지막 빌드 결과 지표
아래 사진과 같이 각 Job별 마지막 빌드가 성공인지, 실패인지 한눈에 볼 수 있는 패널도 만들 수 있다.
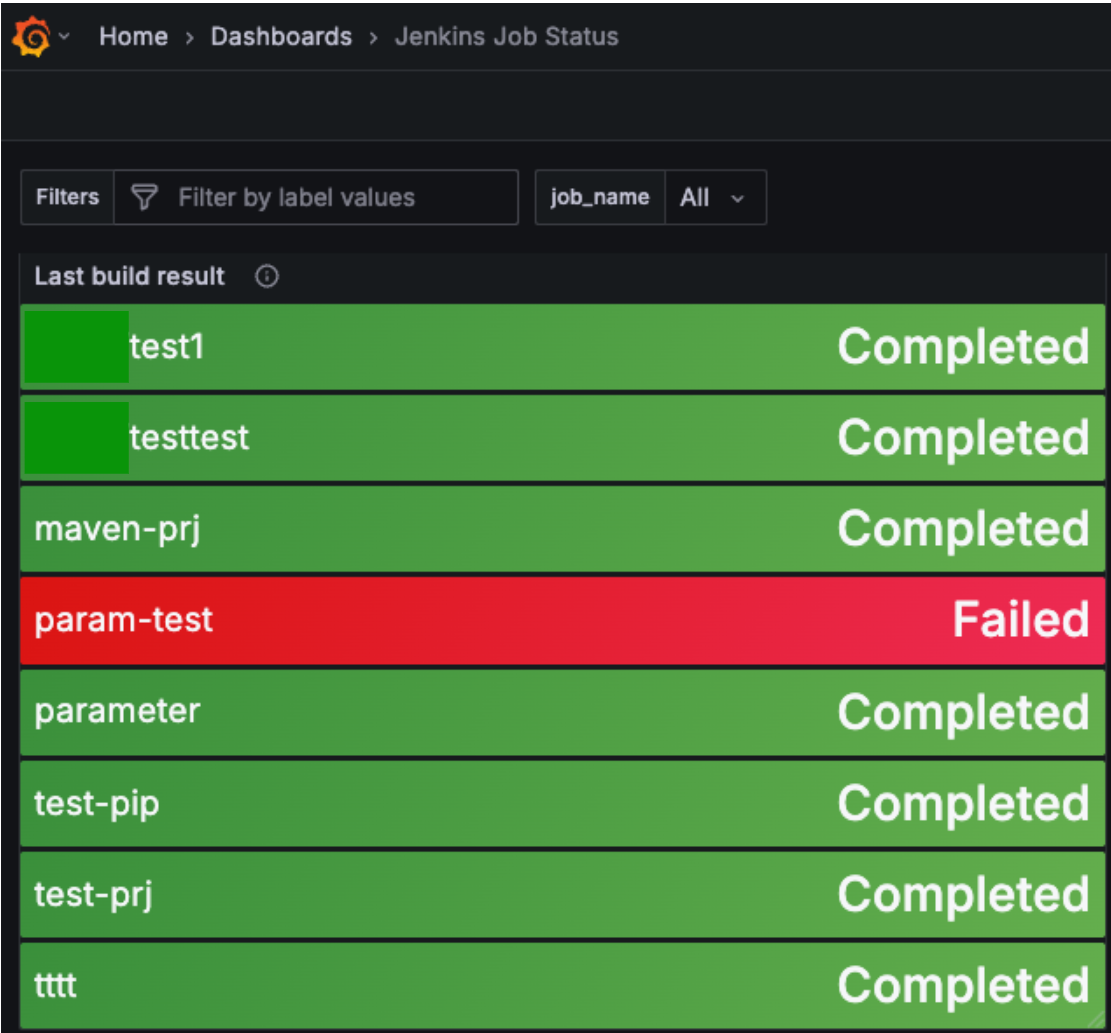
빌드 결과가 성공(SUCCESS) 또는 불안정(UNSTABLE) 상태로 종료되면 1, 빌드가 되지 않은 중단(ABORTED) 또는 실패(FAILURE) 상태로 종료되면 0을 반환하는데, 이 값을 활용해서 패널을 만들면 된다.
Panel 설정 :
- Visualization : Stat
- Metrics borwser : default_jenkins_builds_last_build_result{jenkins_job=~"$job_name"}

- Option :
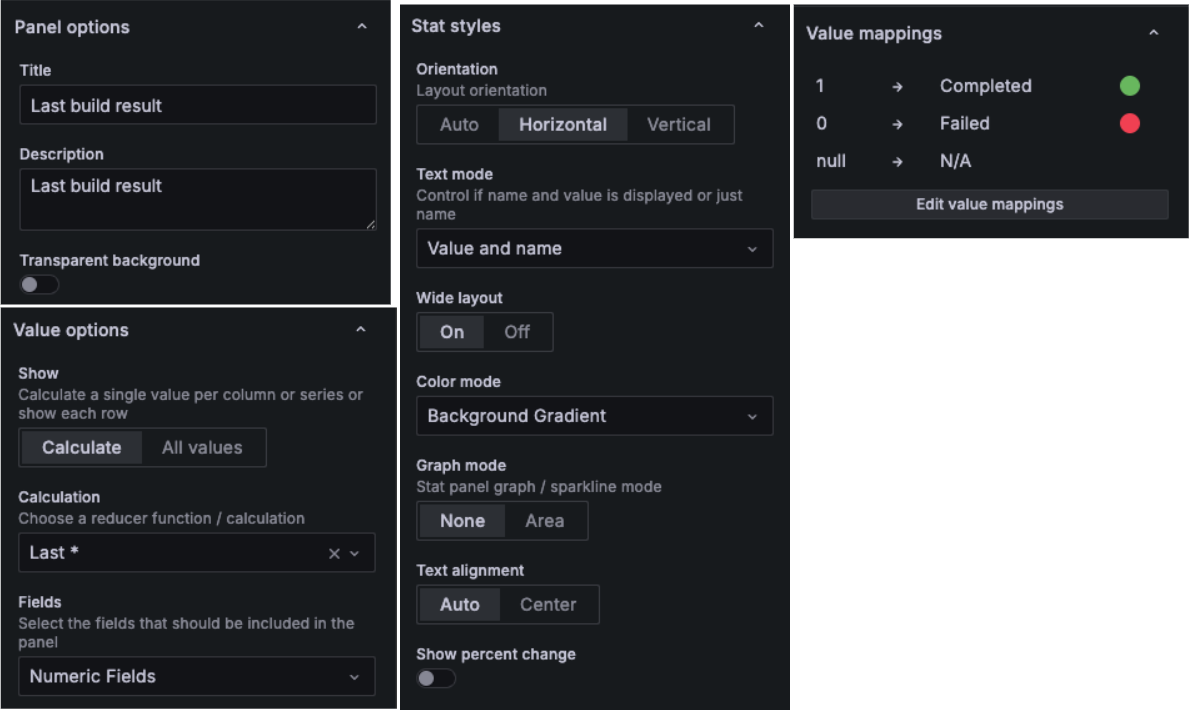
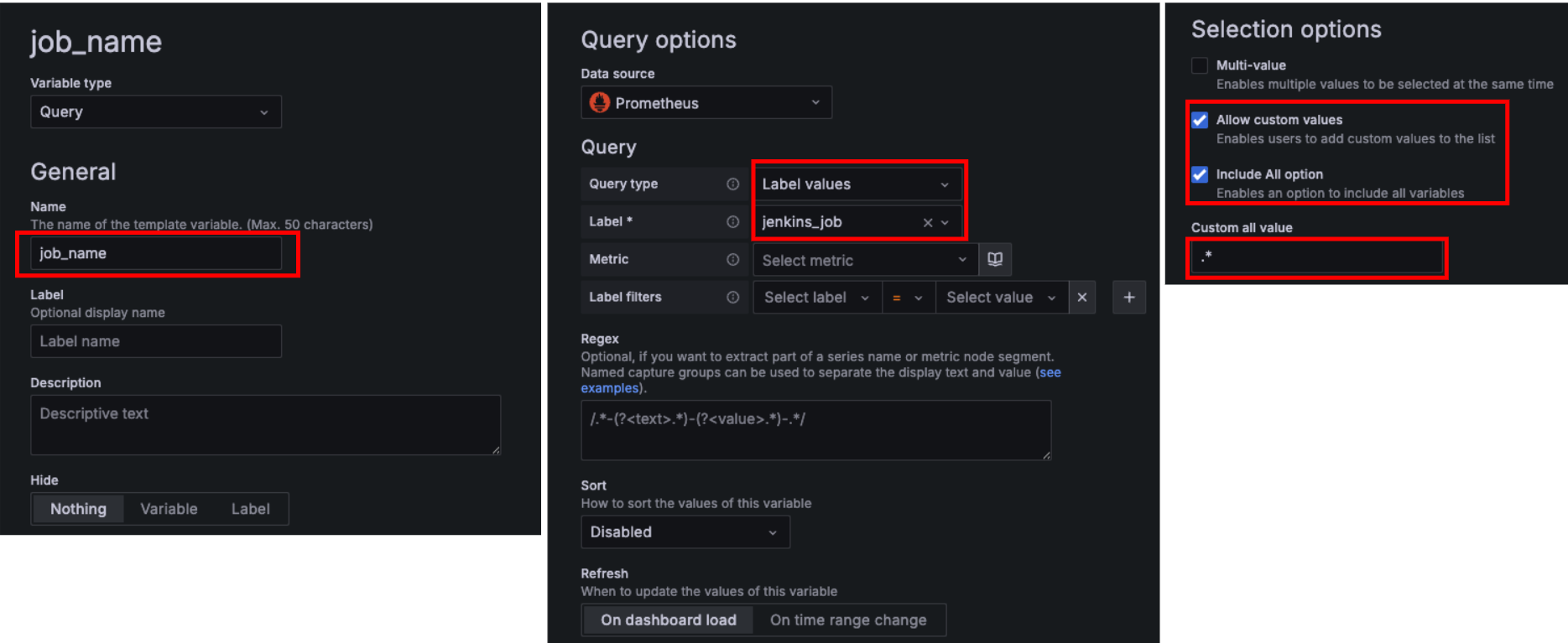
- 변수 :Grafana 대시보드 > Settings → Variables → New variable
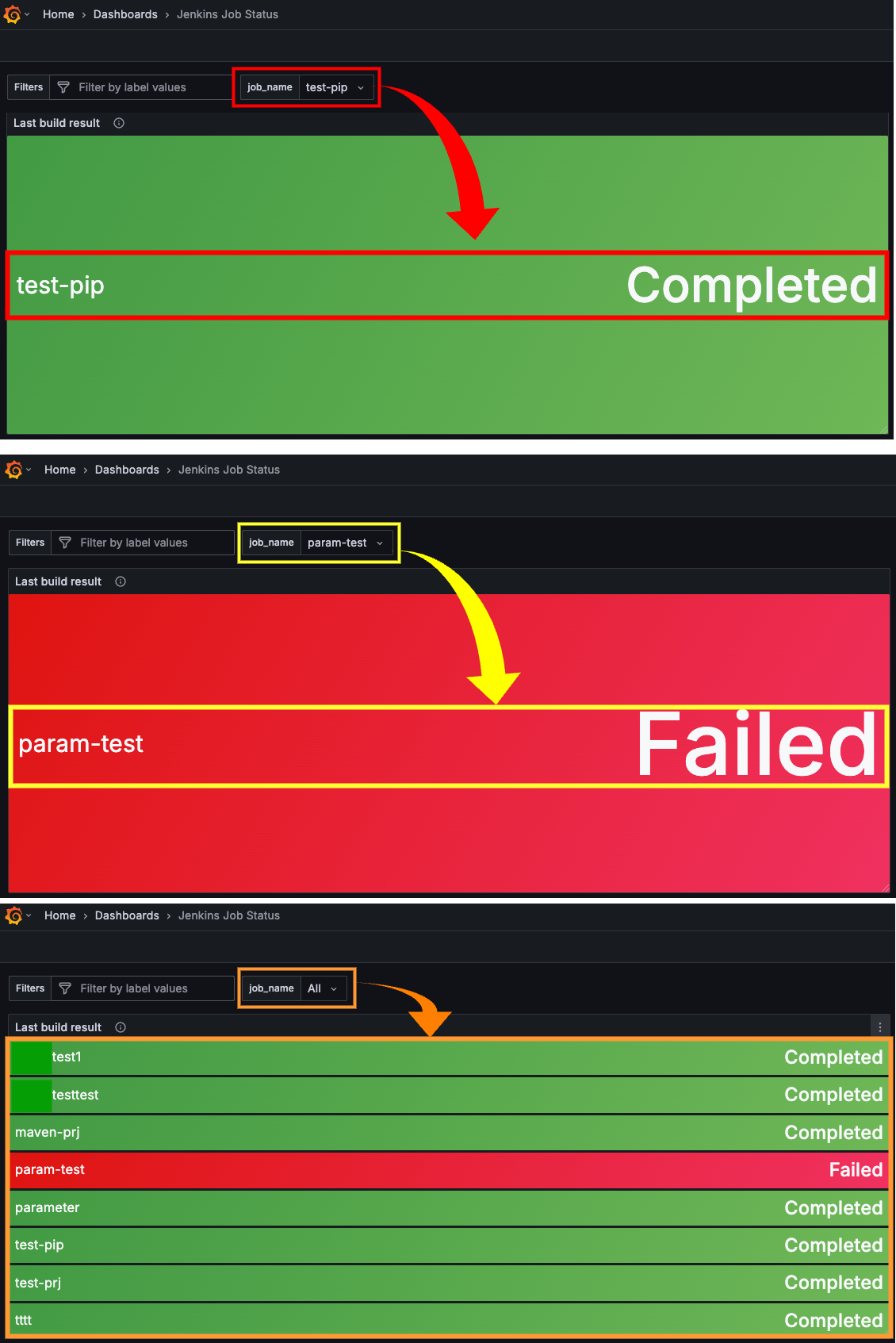
설정이 완료되었으면, 아래와 같이 job name별로 마지막 빌드 상태를 확인할 수 있다.
마무리
이렇게 Jenkins, Prometheus, Grafana를 연동해서 실시간으로 빌드 현황과 주요 지표를 대시보드로 확인하는 방법을 정리해 봤다.
CI/CD 시스템이 커지고 복잡해질수록, 눈으로 바로 확인할 수 있는 모니터링 환경의 효과는 훨씬 커진다.
실제로 실무에서 이런 대시보드를 한번 만들어두면 장애 대응, 품질 관리, 협업까지 모든 면에서 훨씬 수월해진다는 걸 직접 체감하게 된다.
이번 글에서 소개한 방식은 쿠버네티스, 온프레미스, 어떤 환경이든 오픈소스만으로 바로 적용할 수 있기 때문에 팀 단위, 개인 테스트, 엔터프라이즈 어디든 부담 없이 도입해 볼 수 있다.
각자의 환경에 맞게 필요한 패널, 경고 조건 등 더 다양한 커스터마이징을 추가해 보고 조직에 맞는 DevOps 모니터링 체계를 만들어보자.
'CICD > Jenkins' 카테고리의 다른 글
| [Jenkins] Kubernetes Secret으로 Jenkins Credentials 안전하게 관리하기 (with ESO) (0) | 2025.03.27 |
|---|---|
| [Jenkins]로 가상 머신(VM) 환경에 배포하기 (with Pipeline) (0) | 2024.06.20 |
| [Jenkins]란? 개념부터 설치 실행까지 (쿠버네티스 환경) (0) | 2023.12.23 |



댓글