Prometheus란?
Prometheus는 시스템 및 서비스의 상태를 모니터링하는 인기 있는 오픈소스 시계열 모니터링 시스템이다.
Prometheus는 다양한 대상(Target)에서 시간 경과에 따른 지표(Metric)를 수집하여 시계열 데이터베이스(Time-Series Database, TSDB) 형태로 저장한다.
메트릭 수집은 주로 HTTP 엔드포인트를 통한 Pull 방식으로 이루어지며, 서비스 디스커버리 기능을 통해 동적인 환경에서도 자동으로 서비스를 탐지하고 모니터링할 수 있다. 또한, Exporter를 활용하여 Prometheus가 기본적으로 지원하지 않는 애플리케이션의 메트릭도 수집할 수 있다.
Prometheus는 자체 쿼리 언어인 PromQL을 제공하며, 이를 통해 다양한 방식으로 메트릭을 집계하고 필터링할 수 있다. 쿼리 결과는 Grafana와 같은 시각화 도구를 통해 그래프와 대시보드 형태로 표현하여 확인할 수 있다. 또한, 알림 규칙을 정의하고, 임계값을 초과하는 등의 문제가 발생하면 알림를 발송하여 운영자가 신속하게 문제를 인지하고 대응할 수 있도록 돕는다.
Prometheus의 핵심 개념
Time Series (시계열)
Prometheus에서 데이터를 저장하는 기본 단위는 시계열(Time Series)이다.
시계열은 "어떤 메트릭에 대해 시간별로 수집된 값의 흐름"을 의미한다.
같은 메트릭 이름과 같은 레이블 조합이면 같은 시계열이 된다.
예시)
http_requests_total{method="GET", status="200"} 1609459200 100
http_requests_total{method="GET", status="200"} 1609462800 150
http_requests_total{method="GET", status="200"} 1609466400 200위는 "GET 요청이 성공적으로 처리된 횟수"를 시간에 따라 기록한 시계열이다.
Sample (샘플)
샘플은 시계열에서 특정 시점의 값을 나타내는 실제 데이터 포인트라고 이해하면 된다.
각 샘플은 "언제(Timestamp)"에 "무슨 값(Value)"이었는지를 담고 있다.
예시)
http_requests_total{method="GET"} => [1700000000, 100]위는 "1700000000초(Unix 시간 기준) 시점에 GET 요청이 100번 발생했다"는 의미이다.
Metric Name (메트릭 이름)
메트릭 이름은 "이게 어떤 데이터인가?"를 알려주는 이름이다.
예를 들어 위 예시에서 http_requests_total은 "HTTP 요청 수"라는 메트릭을 의미한다.
이름은 ASCII 알파벳, 숫자, 밑줄(_), 콜론(:) 정도만 쓸 수 있고, 아래 정규식을 따르면 된다.
[a-zA-Z_:][a-zA-Z0-9_:]*주의
콜론(:)은 주로 Prometheus 내부에서 쓰는 용도로, 일반적인 계측에서는 사용하지 않는 것이 좋다.
Labels (레이블)
Prometheus에서 레이블은 메트릭을 더 세밀하게 구분할 수 있는 키-값 쌍이다. 각 시계열은 하나의 메트릭 이름과 함께 여러 개의 레이블을 가질 수 있다. 예를 들어 http_requests_total이라는 메트릭이 있으면, method나 handler 같은 레이블을 붙여서 어떤 요청인지 더 구체적으로 알 수 있다.
예시)
http_requests_total{method="POST", handler="/api/test"}위는 method, handler가 레이블 이름이고, POST, /api/test는 각각 그에 대응하는 값이다.
이렇게 레이블을 사용하면, POST 방식으로 /api/test에 요청한 경우만 따로 분리해서 볼 수 있게 해 준다. 즉, 메트릭을 더 세부적으로 추적할 수 있게 된다.
레이블의 특징
- 레이블 이름은 반드시 영문자로 시작해야 하며, 영문자, 숫자, 밑줄(_)을 포함할 수 있다. 단, __ (언더스코어 두 개)로 시작하는 이름은 Prometheus에서 내부적으로 사용하는 예약어이므로 사용하면 안 된다.
- 레이블 값은 유니코드 문자를 포함한 모든 문자를 사용할 수 있다. 그렇기 때문에 매우 유연하게 다양한 값을 설정할 수 있다.
레이블 값의 변화와 카디널리티
레이블에서 중요한 점은 레이블 값이 변경되면 새로운 시계열이 생성된다는 것이다.
예를 들어, 아래와 같이 두 개는 값이 다르기 때문에 서로 다른 시계열로 취급된다.
http_requests_total{method="POST", handler="/api/test"}
http_requests_total{method="GET", handler="/api/test"}이렇게 레이블 값이 바뀌면, 각기 다른 시계열로 취급되어 카디널리티 문제를 발생시킬 수 있다.
Cardinality (카디널리티)
카디널리티는 메트릭 이름과 레이블 조합으로 생성된 고유 시계열의 수를 의미한다. 즉, "고유한 시계열이 얼마나 많은가"를 나타낸다. 만약 http_requests_total 메트릭에 user_id라는 레이블을 추가하면, 사용자별로 시계열이 생성되기 때문에 시계열 수가 엄청나게 증가할 수 있다.
예시)
http_requests_total{user_id="123"}
http_requests_total{user_id="124"}
...이렇게 사용자 ID별로 레이블이 달라지면, 시계열 수가 기하급수적으로 늘어날 수 있다. 이건 Prometheus 메모리 사용량과 성능에 치명적인 영향을 미칠 수 있어 레이블은 정말 필요한 것만 추가하는 것이 중요하다.
데이터는 어디에, 어떻게 저장될까?
Prometheus는 시계열 데이터를 효율적으로 저장하기 위해 청크(Chunk)와 **WAL(Write-Ahead Log)라는 두 가지 핵심 메커니즘을 사용한다.
Chunk (청크)
- 청크는 여러 개의 샘플을 하나의 덩어리로 묶은 데이터 구조이다. 이 청크는 압축되어 디스크에 저장되며, 조회 성능도 뛰어나게 최적화된다. 이렇게 압축된 청크 덕분에 Prometheus는 많은 데이터를 효율적으로 저장하고 빠르게 조회할 수 있게 된다.
WAL (Write-Ahead Log)
- WAL은 데이터의 안정성을 보장하는 로그 파일이다. 샘플이 수집되면 가장 먼저 WAL에 기록된다. 이는 장애 발생 시 복구를 돕는 중요한 역할을 한다. 예를 들어, Prometheus가 비정상 종료되었을 때 WAL 파일을 읽어 데이터를 복원할 수 있다.
아래는 Prometheus에서 WAL과 chunk가 어떻게 상호작용하여 데이터를 저장하는지에 대한 흐름 설명이다.
- Prometheus는 타겟으로부터 메트릭을 수집하고, 이를 시계열 데이터로 변환한다.
- 수집된 메트릭은 Prometheus의 in-memory TSDB 구조에 시계열(series)과 샘플(sample) 형태로 저장된다.
- 동시에, 수집된 샘플과 해당 시계열 정보는 Write-Ahead Log(WAL)에도 기록되어 장애 발생 시 복구 가능하게 한다.
- 메모리 내의 샘플들은 chunk로 압축되어 저장되며, 일정 시간이 경과하거나 조건이 충족되면 디스크에 block 형태로 flush 된다. 이후 해당 시점까지의 WAL segment는 삭제된다.
- 디스크에 저장된 block들은 주기적으로 compaction 과정을 거치며, 이 과정에서 저장 공간을 최적화한다.
- Prometheus가 재시작되면, 메모리에만 존재하던 데이터를 복구하기 위해 WAL을 읽어 시계열과 샘플 정보를 다시 메모리에 로드하여 데이터의 연속성을 유지한다.
프로메테우스의 구조는 다음과 같다.

참고: https://prometheus.io/docs/introduction/overview/#architecture
각 기능들에 대해 설명하자면 다음과 같다.

Prometheus의 Retrieval은 Service discovery에 정의되어 있는 Target을 식별하고 메트릭 데이터를 주기적으로 수집하는 역할을 담당한다. Kubernetes 클러스터에서는 Kubernetes Service Discovery를 사용하여 클러스터 내에서 실행 중인 서비스를 자동으로 검색하고 모니터링할 수 있다.

Exporters는 Prometheus에서 기본적으로 모니터링할 수 없는 서비스나 애플리케이션으로부터 메트릭을 수집하는 데 사용된다. 즉, 시스템의 메트릭 데이터를 Prometheus가 이해할 수 있는 형식으로 변환하여 노출시켜 주는 기능을 하며, Prometheus Retrieval가 이 메트릭을 가져와 처리한다.

Pushgateway는 짧은 지속 시간의 작업 (예: 배치 작업, 일회성 작업)에서 발생하는 메트릭을 Push 방식으로 수집하는 역할을 한다. Prometheus 서버는 설정된 수집 주기에 따라 Retrieval을 통해 Pushgateway로부터 해당 메트릭을 Pull 방식으로 수집한다.

Prometheus는 알림이 생성되면 Alertmanager가 사용하는 HTTP API를 통해 알림을 전송한다. Alertmanager는 Prometheus가 생성한 알림을 수신하고 필터링, 그룹화, 전달 등의 작업을 수행하여 최종적으로 수신자에게 전송하는 역할을 한다. 수신자는 Email이 될 수 있고, webhook 알림을 받을 수 있는 다른 시스템일 수도 있다.
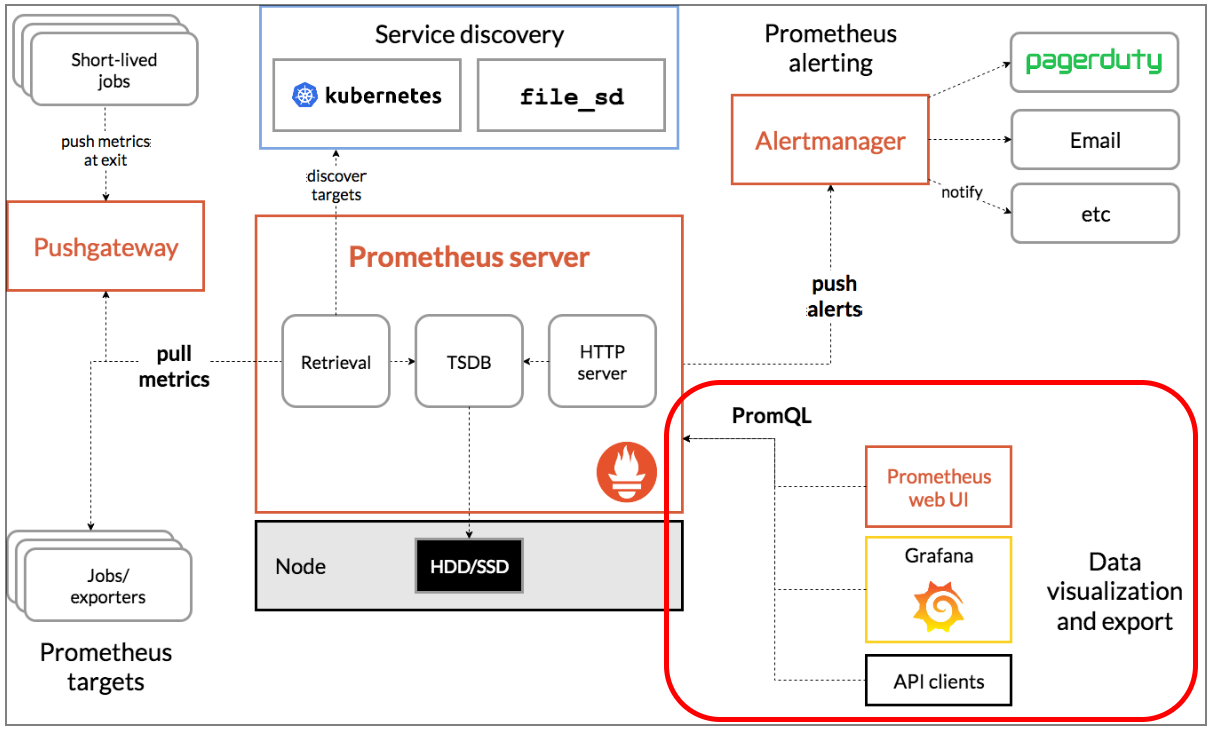
Prometheus HTTP Server는 Prometheus에서 수집한 메트릭 데이터를 HTTP 엔드포인트로 노출하는 역할을 한다. 이를 통해 웹 브라우저 또는 다른 애플리케이션(예: Grafana)에서 쿼리하고 데이터를 시각화할 수 있다.
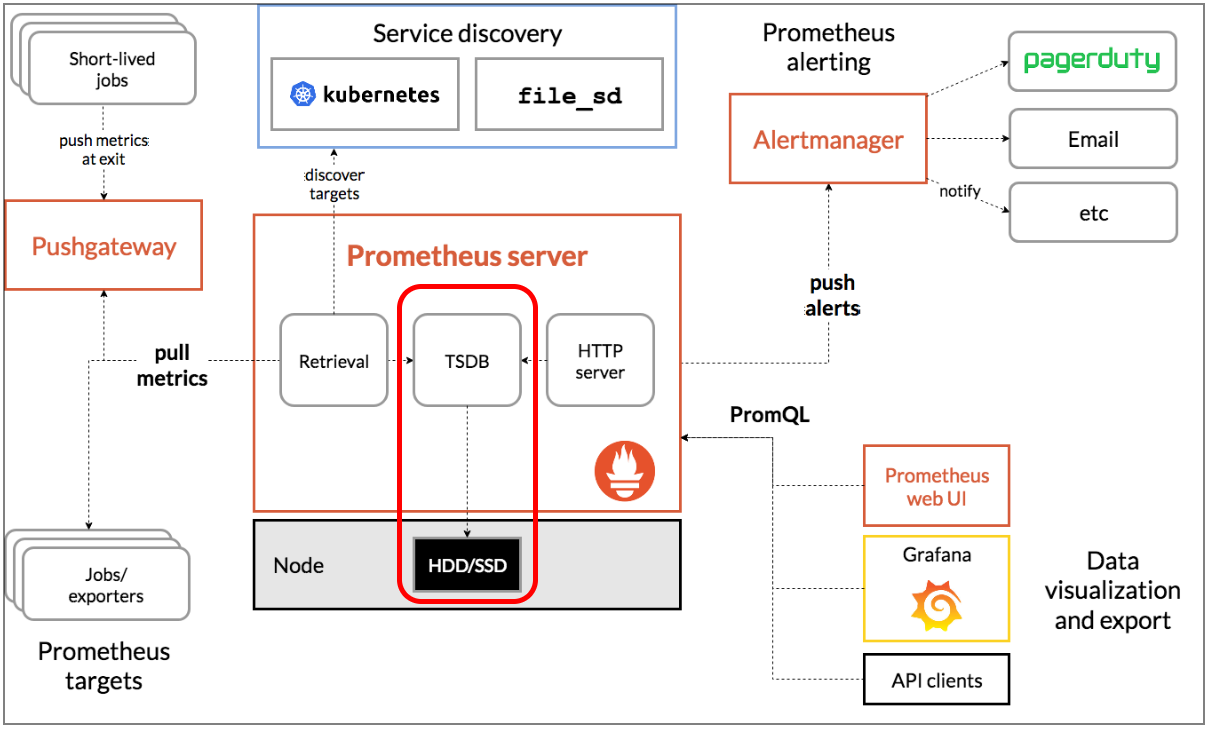
Prometheus는 모든 수집한 시계열 데이터를 Local Storage에 TSDB(Time Series Database) 형식으로 저장하여 보관한다.
마무리
Prometheus는 처음엔 단순한 메트릭 수집 기반의 모니터링 도구처럼 보이지만, 써볼수록 얼마나 정교하게 설계된 시스템인지 알 수 있다. 메트릭의 수집부터 저장, 알림 전송까지 모든 과정을 자체적으로 처리할 수 있고, 다양한 환경에서도 유연하게 동작한다는 점에서 모니터링 시스템의 기반으로 충분히 고려해 볼 만한 도구인 것 같다.
다만, 대규모 시스템에서의 확장성이나 장기 보존 기간에 대한 제약은 Prometheus의 치명적인 단점이기 때문에, 이러한 특성을 잘 고려한 후 선택하는 것이 중요하다.
'Observability > Prometheus & Grafana' 카테고리의 다른 글
| [Grafana Loki]란? 개념부터 설치까지 (2) | 2023.11.01 |
|---|---|
| [Prometheus] HA 구성 2 (With 샤딩 + Thanos) (3) | 2023.05.10 |
| [Grafana] + AWS CloudWatch를 이용한 AWS 모니터링 (0) | 2023.05.09 |
| [Grafana] 대시보드 Variables 활용하기 (0) | 2023.05.04 |
| [Prometheus] HA 구성 1 (with Thanos) (4) | 2023.05.03 |




댓글