일반적으로 Helm chart(prometheus-community.github.io)를 사용하여 Prometheus를 설치하면 node-exporter와 kube-state-metrics 수집기가 기본으로 활성화되어 Kubernetes 리소스 관련 메트릭 데이터를 자동으로 수집한다. (관련 구성 참고 :Prometheus + Grafana 설치)
이번 글에서는 Prometheus에서 기본으로 제공하는 수집기가 아닌 opentelmetry 수집기를 사용하여 메트릭을 수집하는 실습을 다룰 것이다. 그렇기 때문에 기본으로 제공하는 Prometheus 수집기 및 Scrape 설정을 모두 비활성화 후 구성해야 한다.
OpenTelemetry exporter에서 prometheus로 metric을 전송하는 방법은 두 가지가 있다.
- prometheusremotewrite
- opentelemetry-collector에서 prometheus 서버로 전송하는 push 방식 - prometheus
- opentelemetry-collector에서 metric을 노출시키고 prometheus 서버가 pull 하는 방식
본 글에서는 prometheusremotewrite 방식을 사용하여 구성할 것이다.
또한 prometheusremotewrite, prometheus 방식을 사용했을 때 Prometheus 서버에 CPU 사용률 차이가 있는지도 확인해 볼 것이다.
아래 그림을 참고하자.

Prometheus Reciver로 노드의 metric을 수집, memory_limiter, batch Processor로 수집된 metric에 대해 제한 및 필터, prometheusremotewrite Exporter로 Prometheus 서버로 수집된 metric을 전송하는 구조이다.
실습
전제 조건
- AWS EKS 클러스터
- Helm CLI 도구
구성 환경
- AWS EKS 1.24.17
- Helm v3.8.2
설치 버전
- kube-prometheus-stack helm chart : 48.1.1
- grafana helm chart : 6.60.4
- opentelemetry-collector helm chart : 0.62.2
1. Prometheus 구성
Prometheus helm chart repo를 등록한다.
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm repo update
values 파일을 아래와 같이 작성한다.
## prometheus-values.yaml
alertmanager:
serviceMonitor:
selfMonitor: false
grafana:
enabled: false
kubernetesServiceMonitors:
enabled: false
kubeApiServer:
enabled: false
kubelet:
enabled: false
kubeControllerManager:
enabled: false
coreDns:
enabled: false
kubeDns:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
kubeProxy:
enabled: false
kubeStateMetrics:
enabled: false
kube-state-metrics:
prometheus:
monitor:
enabled: false
nodeExporter:
enabled: false
prometheus-node-exporter:
prometheus:
monitor:
enabled: false
prometheusOperator:
enabled: true
resources:
limits:
cpu: 150m
memory: 300Mi
requests:
cpu: 150m
memory: 300Mi
kubeletService:
enabled: false
serviceMonitor:
selfMonitor: false
prometheus:
enabled: true
serviceMonitor:
selfMonitor: false
prometheusSpec:
enableRemoteWriteReceiver: true
위에서 생성한 prometheus-values.yaml 파일을 사용하여 설치한다.
$ kubectl create ns monitoring
$ helm upgrade -i prometheus -f prometheus-values.yaml prometheus-community/kube-prometheus-stack \
--namespace monitoring
Prometheus 기본 수집기 없이 설치되었는지 확인한다.
$ kubectl get po -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-prometheus-kube-prometheus-alertmanager-0 2/2 Running 0 2m57s
prometheus-grafana-765bfdb8b9-5xxq8 3/3 Running 0 3m5s
prometheus-kube-prometheus-operator-68b56fb774-qtfqc 1/1 Running 0 3m5s
prometheus-prometheus-kube-prometheus-prometheus-0 2/2 Running 0 2m56s
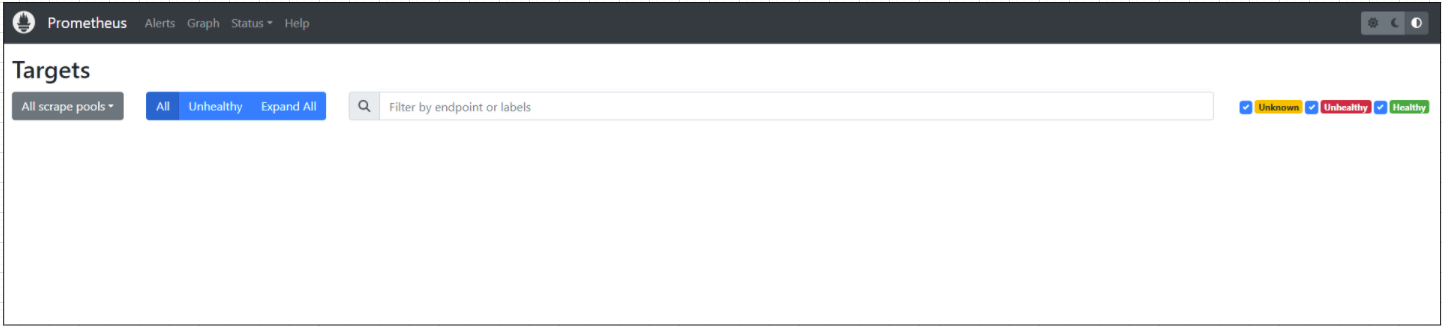
Prometheus UI에 접근해서 Targets을 확인해 보면 아무것도 없는 것을 확인할 수 있다.
2. Granfana 구성
Grafana helm chart repo를 등록한다.
$ helm repo add grafana https://grafana.github.io/helm-charts
$ helm repo update
Grafana values.yaml 파일을 작성한다.
## grafana-values.yaml
adminPassword: test
adminUser: test
persistence:
enabled: true
size: 10Gi
storageClassName: "{각 환경에서 사용하는 StorageClass 이름}"
type: pvc
rbac:
namespaced: true
pspEnabled: false
replicas: 1
위에 작성된 grafana-values.yaml 파일을 사용하여 설치한다.
$ helm upgrade -i grafana -n monitoring -f grafana-values.yaml grafana/grafana
설치가 완료되면 Grafana 대시보드에 들어가서 로그인한다. ID/Password는 grafana-values.yaml 파일에서 설정한 test/test 이다.

로그인 후 prometheus 서버를 datasource로 지정하여 생성한다.
- Toggle menu > Data sources > Add data source > Prometheus
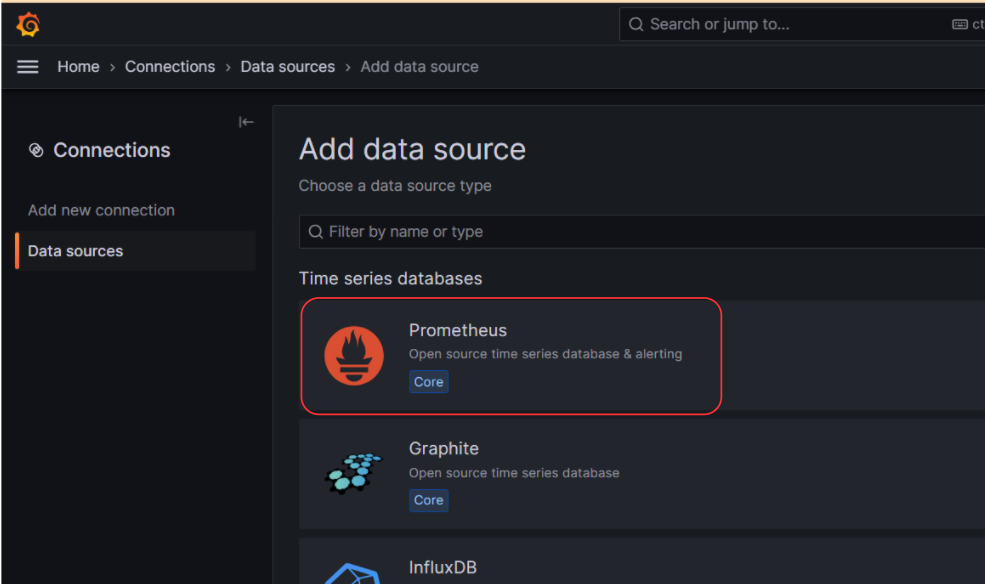
Prometheus server URL에 Kubernetes service dns 및 Prometheus 포트 9090을 입력 후 Save & test 버튼을 클릭한다. Successfully queried the Prometheus API. 문구가 나오면 정상적으로 연결이 된 것이다.
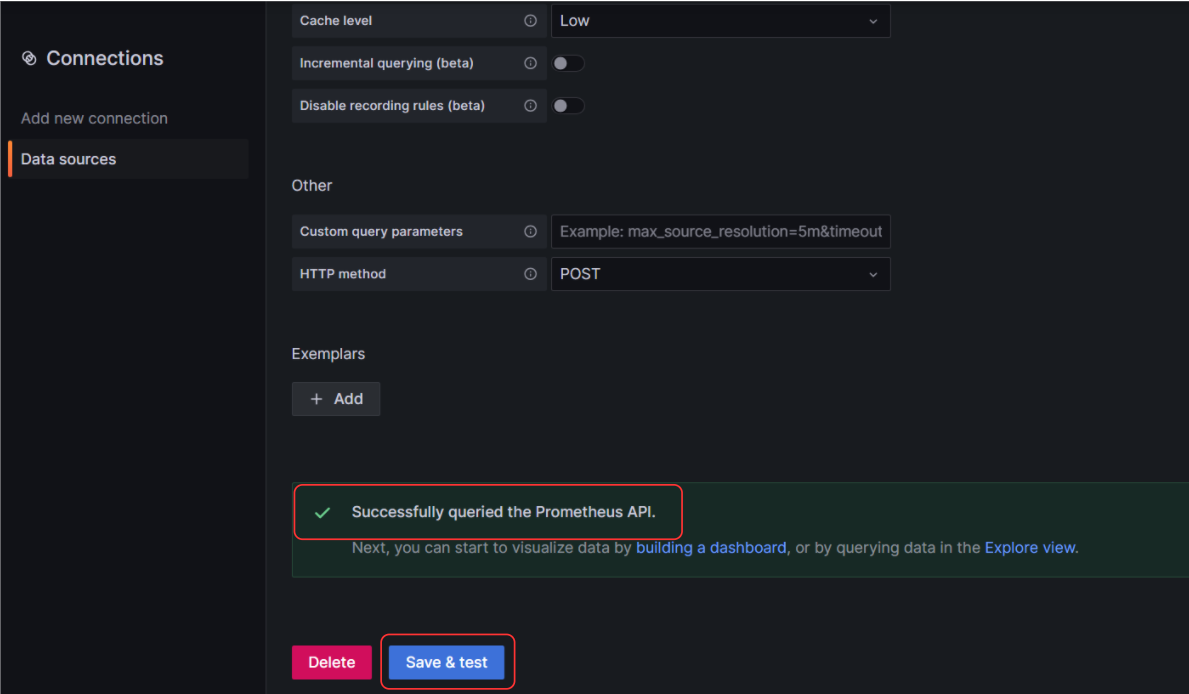
Data sources에 등록된 것을 확인할 수 있다.
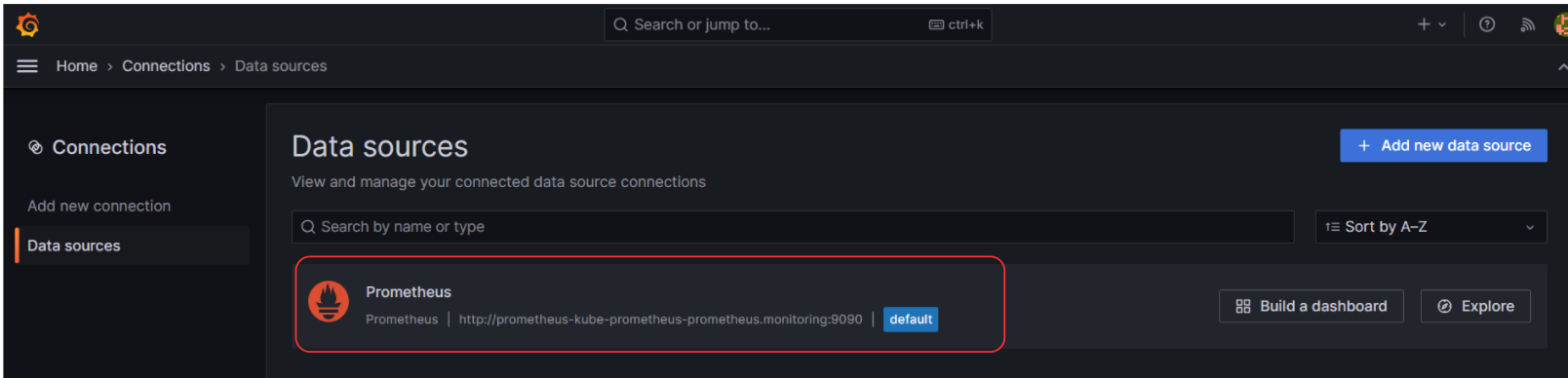
3. OpenTelemetry Collector 구성
OpenTelemetry helm chart repo를 등록한다.
$ helm repo add open-telemetry https://open-telemetry.github.io/opentelemetry-helm-charts
$ helm repo update
values 파일을 아래와 같이 작성한다.
## otel_values.yaml
mode: daemonset
clusterRole:
create: true
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
- nodes
- nodes/proxy
- services
- endpoints
verbs:
- get
- watch
- list
- apiGroups:
- extensions
resources:
- ingresses
verbs:
- get
- list
- watch
- nonResourceURLs:
- /metrics
verbs:
- get
config:
exporters:
prometheusremotewrite:
endpoint: "http://prometheus-kube-prometheus-prometheus.monitoring.svc.cluster.local:9090/api/v1/write"
tls:
insecure: true
external_labels:
label_name: $KUBE_NODE_NAME
logging:
verbosity: detailed
extensions:
health_check: {}
memory_ballast:
size_in_percentage: 33
processors:
batch: {}
memory_limiter:
check_interval: 5s
limit_percentage: 75
spike_limit_percentage: 25
receivers:
jaeger: null
prometheus:
config:
global:
scrape_interval: 60s
scrape_timeout: 30s
scrape_configs:
- job_name: kubernetes-nodes-cadvisor
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- replacement: kubernetes.default.svc:443
target_label: __address__
- regex: (.+)
replacement: /api/v1/nodes/$$1/proxy/metrics/cadvisor
source_labels:
- __meta_kubernetes_node_name
target_label: __metrics_path__
- action: keep
regex: $KUBE_NODE_NAME
source_labels: [__meta_kubernetes_node_name]
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
- job_name: kubernetes-nodes
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- replacement: kubernetes.default.svc:443
target_label: __address__
- regex: (.+)
replacement: /api/v1/nodes/$$1/proxy/metrics
source_labels:
- __meta_kubernetes_node_name
target_label: __metrics_path__
- action: keep
regex: $KUBE_NODE_NAME
source_labels: [__meta_kubernetes_node_name]
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
- job_name: kubernetes-service-endpoints
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scrape
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scheme
target_label: __scheme__
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $$1:$$2
source_labels:
- __address__
- __meta_kubernetes_service_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_service_annotation_prometheus_io_param_(.+)
replacement: __param_$$1
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_service_name
target_label: kubernetes_name
- action: replace
source_labels:
- __meta_kubernetes_pod_node_name
target_label: kubernetes_node
- action: keep
regex: $KUBE_NODE_NAME
source_labels: [__meta_kubernetes_endpoint_node_name]
- job_name: kubernetes-pods
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scheme
target_label: __scheme__
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $$1:$$2
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_annotation_prometheus_io_param_(.+)
replacement: __param_$$1
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: kubernetes_pod_name
- action: drop
regex: Pending|Succeeded|Failed|Completed
source_labels:
- __meta_kubernetes_pod_phase
- action: keep
regex: $KUBE_NODE_NAME
source_labels: [__meta_kubernetes_pod_node_name]
zipkin: null
service:
extensions:
- health_check
- memory_ballast
pipelines:
logs: null
metrics:
exporters:
- prometheusremotewrite
processors:
- memory_limiter
- batch
receivers:
- prometheus
traces: null
telemetry:
metrics:
address: 0.0.0.0:8888
level: normal
extraEnvs:
- name: KUBE_NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
ports:
metrics:
containerPort: 8888
enabled: true
protocol: TCP
servicePort: 8888위 설정(config) 중 아래 설정은 알아두어야 한다.
[extensions] : 수집기의 기본 기능 외에 추가 기능을 제공한다.
- memory_ballast (설정 권장)
- 메모리 관리를 안정화하고 성능을 최적화하는 데 사용되는 메커니즘이다. 이 설정은 수집기에 할당된 메모리의 1/3 ~ 1/2로 구성하는 것을 권장한다. 위에서는 33%로 설정하였다.
- 내용 참고 : https://web.archive.org/web/20210929130001/https://blog.twitch.tv/en/2019/04/10/go-memory-ballast-how-i-learnt-to-stop-worrying-and-love-the-heap-26c2462549a2/
- 옵션 참고 : https://github.com/open-telemetry/opentelemetry-collector/blob/main/extension/ballastextension/README.md
[pipelines]
- receivers
- prometheus
- prometheus scrape 설정을 통해 metrics 데이터를 수집한다.
- 위 수집기 설정은 daemonset 형태로 각 노드에 배포되기 때문에 노드마다 배포된 수집기가 중복된 데이터를 수집하지 않게 하기 위해 수집기가 위치한 노드에 존재하는 메트릭을 수집하게 하기 위한 설정이다.
- prometheus
- processors
- memory_limiter (설정 권장)
- 수집기의 메모리 부족 상황을 방지하기 위해 사용을 제한하는 기능이다.
- 위 설정의 경우 5초마다 최대 메모리에 75퍼센트까지 사용 제한하고 순간적으로 25프로까지 사용할 수 있게 메모리 사용이 튀는 증상을 방지한다.
- 옵션 참고 : https://github.com/open-telemetry/opentelemetry-collector/blob/main/processor/memorylimiterprocessor/README.md - batch (설정 권장)
- 데이터를 압축하고 전송하는 데 필요한 시간 및 사이즈를 지정하여 처리량을 조절할 수 있다.
- memory_limiter 설정에 의해 data drop이 발생하게 되면 이후에 batch 작업이 이루어져야 하고, 이를 최소화하기 위해 memory_limiter 파이프라인 뒤에 실행되어야 한다.
- 옵션 참고 : https://github.com/open-telemetry/opentelemetry-collector/tree/main/processor/batchprocessor
- memory_limiter (설정 권장)
- exporters
- prometheusremotewrite
- receivers를 통해 수집된 prometheus 메트릭 데이터를 원하는 prometheus 서버로 push 한다.
- prometheusremotewrite
위에서 생성한 otel_values.yaml 파일을 사용하여 설치한다.
$ kubectl create ns opentelemetry
$ helm upgrade --install opentelemetry-collector open-telemetry/opentelemetry-collector --namespace opentelemetry -f otel_values.yaml
4. Metric 수집 확인
실제로 OpenTelemetry collector에서 설정한 prometheus receivers 통해 metric 데이터를 수집하여 지정한 Prometheus 서버로 잘 보내지고 있는지 Grafana에서 확인한다.
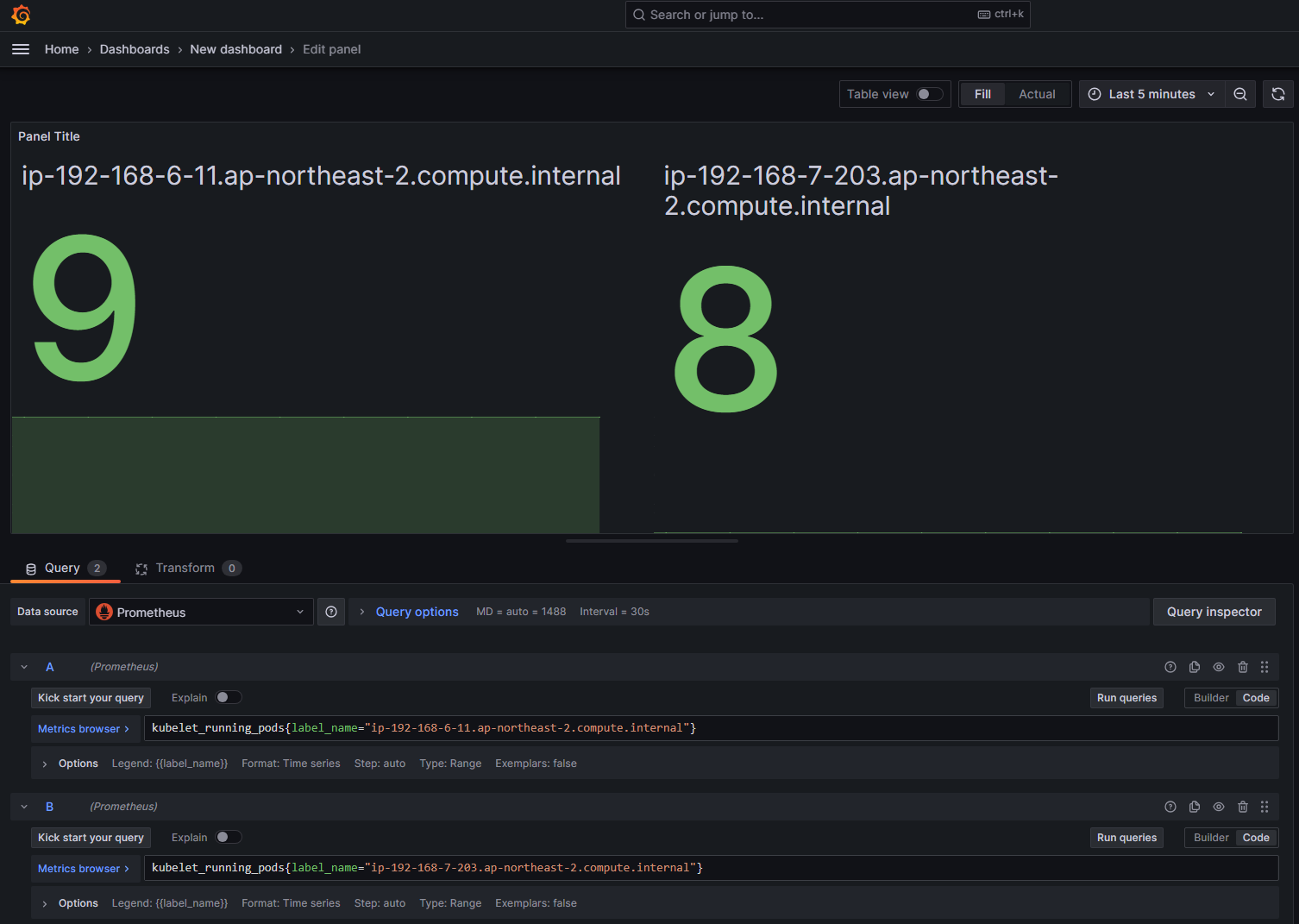
"kubelet_running_pods"는 pod의 개수를 알려주는 쿼리이다.
위에서 설정한 otel_values.yaml 파일의 config.exporters.external_labels 설정에서 "label_name: $KUBE_NODE_NAME" 으로 설정했기 때문에 해당 label을 통해 각 노드에 존재하는 opentelemetry-collector가 수집하는 pod의 개수를 확인할 수 있다.
실제로 위 값이 각 노드에 존재하는 pod의 개수와 같은지 확인한다.
$ kubectl get po -o wide -A --no-headers | grep ip-192-168-7-203.ap-northeast-2.compute.internal | wc -l
8
$ kubectl get po -o wide -A --no-headers | grep ip-192-168-6-11.ap-northeast-2.compute.internal | wc -l
9
5. OpenTelemetry Prometheus push, pull 방식 CPU 사용률 비교
아래는 Opentelemetry-collector exporter의 prometheusremotewrite(push)와 prometheus(pull) 두 개의 방식을 번갈아가면서 사용 후 Prometheus 서버의 CPU 사용률을 비교한 사진이다.
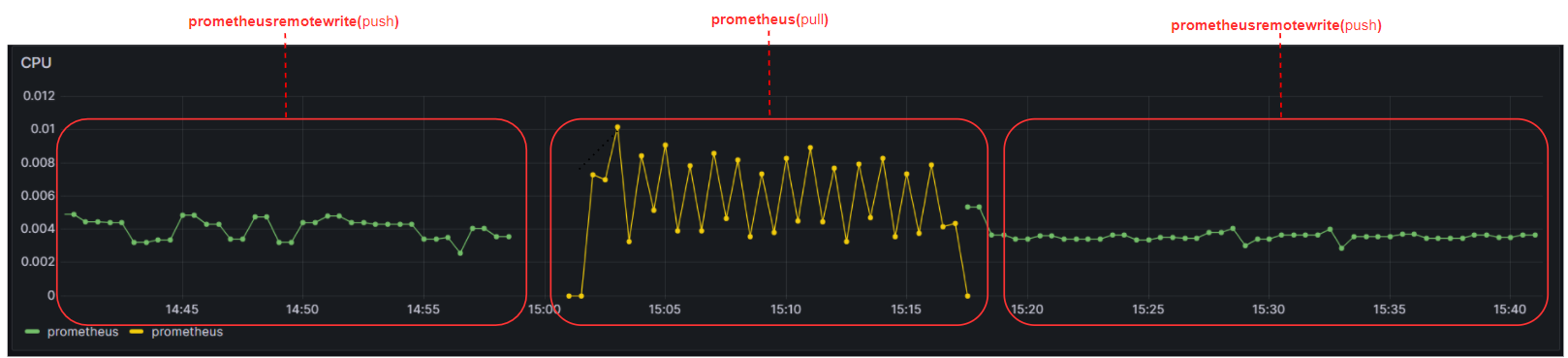
prometheusremotewrite 방식으로 사용하면 Prometheus 서버의 scrape 작업 부하를 줄여주니 CPU를 적게 사용하는 것을 확인할 수 있다.
'Observability > Opentelemetry' 카테고리의 다른 글
| [Opentelemetry]를 사용하여 AWS EKS 환경 로그 모니터링 구성하기 (with Grafana Loki + Grafana) (3) | 2023.10.31 |
|---|---|
| [OpenTelemetry]란? (0) | 2023.09.18 |


댓글